Create better experiences for your visitors
For a very long time, I’ve been speculating how to improve the user experience on my blog and more importantly, how to make it more personal for the individual visitors. Websites are rarely personal but almost always focus on the writer or the company that runs the website.
The problem with personalizing a website for visitors that aren’t registered is that they are very anonymous. You only have their IP address and that doesn’t get you very far. On a blog it is very common to set a cookie with name, e-mail address and website URL for visitors that write a comment. That’s so that they don’t have to enter the information again the next time the want to write a comment.
Welcoming widget
With that cookie it is now possible to do a little data mining and provide a little more personalized experience to the visitor. I’ve experimented with a widget that greets the visitor by name and informs if any new comments have been added to the same post as the visitor commented since her last visit. Also, it checks to see if the visitor’s website contains a link to her APML file and then offer the visitor to filter the blog based on that. It looks like this:
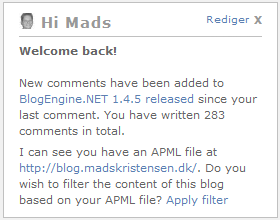
If you have written a comment on this blog and haven’t deleted your cookie, then you should see it live in the top right corner on this page.
Comment statistics
Another thing I thought would create a better experience is to make it easy to show all the comments made by a single comment author. That makes it easy for any given visitor to check up on all her own comments as well as comments made by others. It works for trackbacks and pingbacks as well.
It looks like this:
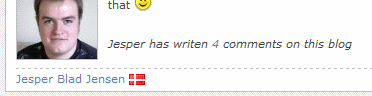
The number, in this case 4, is a link to the search page that lists the 4 comments made by this commentor. It doesn’t rely on the visitor having a cookie, so everyone will be able to see this information.
Get more personal
This is just the beginning. The amount of information that is retrievable by a website URL, such as FOAF, SIOC, APML and various microformats, makes it possible to create an even more personalized experience. I’m not out of ideas yet, but I would very much like to hear from you what types of personalizations you would like on a blog or website.
I think we are at the beginning of this type of cloud mining and that will eventually lead to some very cool personalized services.
Download
The extension that shows the number of comments made by a visitor is plug ‘n play in BlogEngine.NET 1.3+. The widget works only for BlogEngine.NET 1.4.5.6 that you can download at CodePlex. However, you can easily make it work for BlogEngine.NET 1.4.5 by removing the call to the CompressionModule on line 23.